The role of Advai in this landscape is to take:
- the rigour of our AI Alignment Framework and its focus on discovering fault tolerances and setting up operational boundaries; and,
- the Adversarial AI breakthroughs we’ve made that ‘teach’ AI models to recognise when they don’t have the information they need to operate reliably,0
and to bring these approaches into training customised reward models that guardrail our clients’ internal language models.
This way, we can ensure that large language models are not only efficient and powerful but also dependable and trustworthy.
Advai's approach connects the command-line development environment of data scientists, to the c-suite and risk-oriented mindset of organisational command. This is achieved through a rigorous robustness, stress-testing and insight ecosystem.
Until now, open LLMs haven’t really competed with the strengths of the heavily protected models developed by Google and OpenAI. However, emerging open LLMs (like Llama 2.0 and it’s integration into the Open Source integration environment of Hugging Face) are opening up the possibility for more widespread organizational adoption. Why? Because they enable customised reward models to fine tune the base LLM model, without significant compromise to the quality of the language system.
It's an exciting prospect, but as these open models become more complex and their business applications more diverse, the potential for unexpected results only increases. A culture of robustness, a customised approach to reward model development, and a suite of automated tools, will be crucial to ensure these models produce the results without the repercussions.
Adversarial Reinforcement Learning is one of the latest approaches in AI research where many discoveries are yet to be made. Like a sparring partner for an AI model, Adversarial approaches continually test and push an AI model’s limits to improve its performance (as a source, we'll cite our own research on this one!).
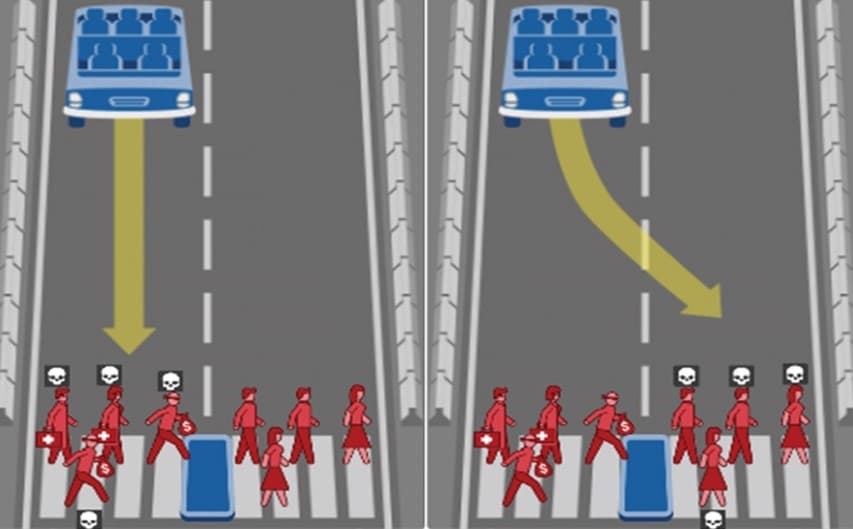
To use the example of a bank again, adversarial RL will be crucial to test as many different possible conversational pathways – to explore as many ‘strange’ pathways – as possible, to ensure banking customers are given accurate and relevant information.
The open-source community, represented by platforms like Hugging Face, is also playing a pivotal role in closing the gap between open-source and proprietary AI technologies. With these platforms, anyone with the computational resources and the right expertise can develop their own language models. As these colossal LLMs (Llama 2.0) become more accessible, the rate of breakthroughs from the Open-source community will increase.
The role of Advai will be to understand the business environment, understand the deeply technical techniques and tools, and to enact this expertise in crafting reward models that prevent unwanted responses.