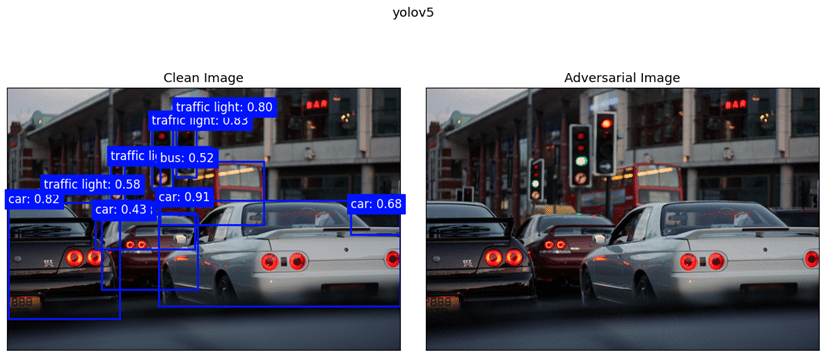
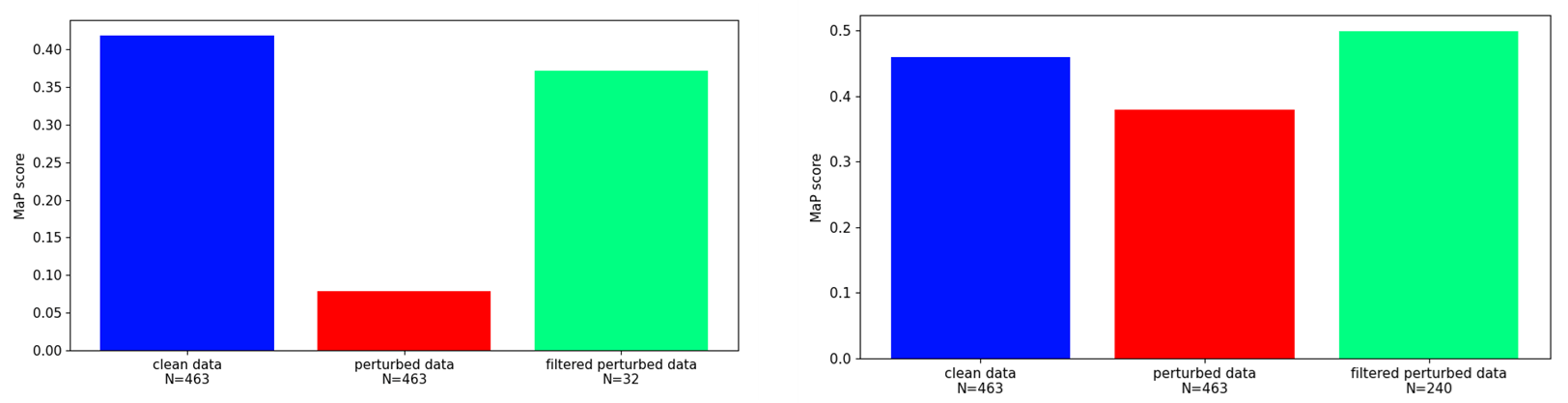
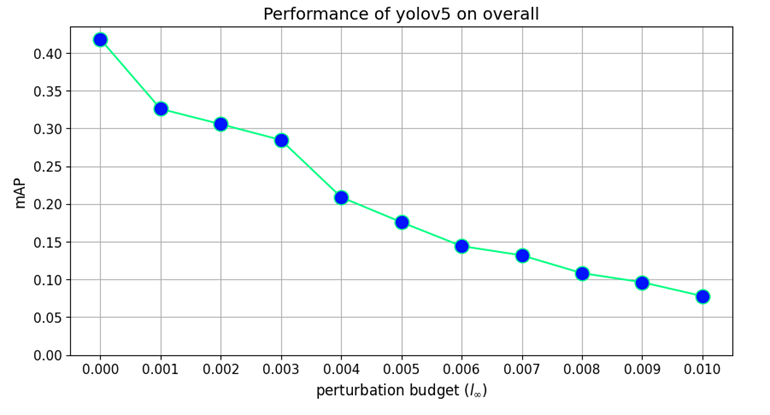
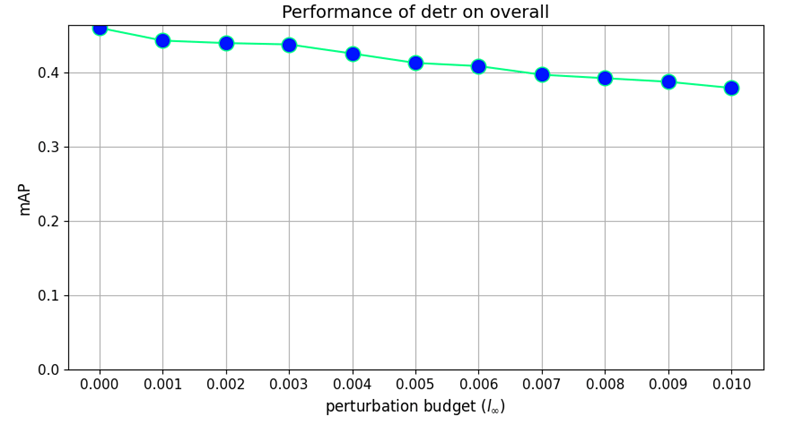
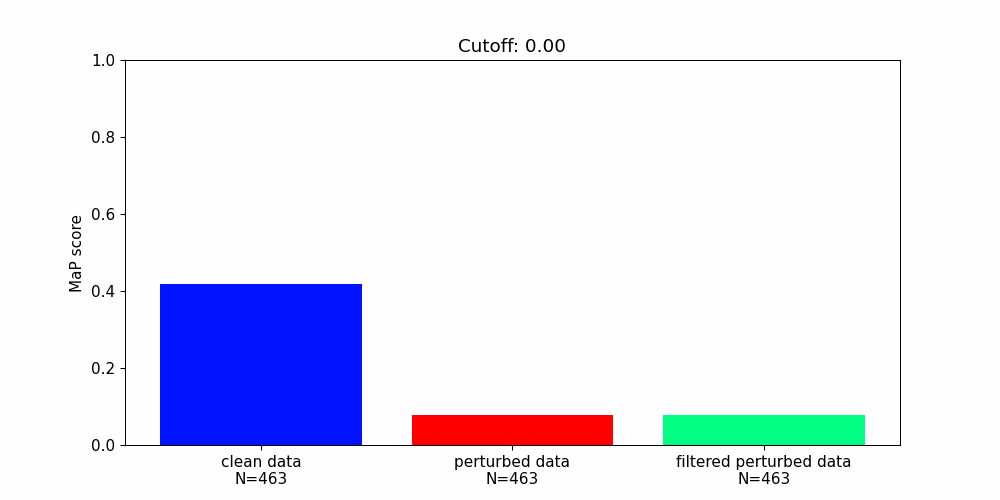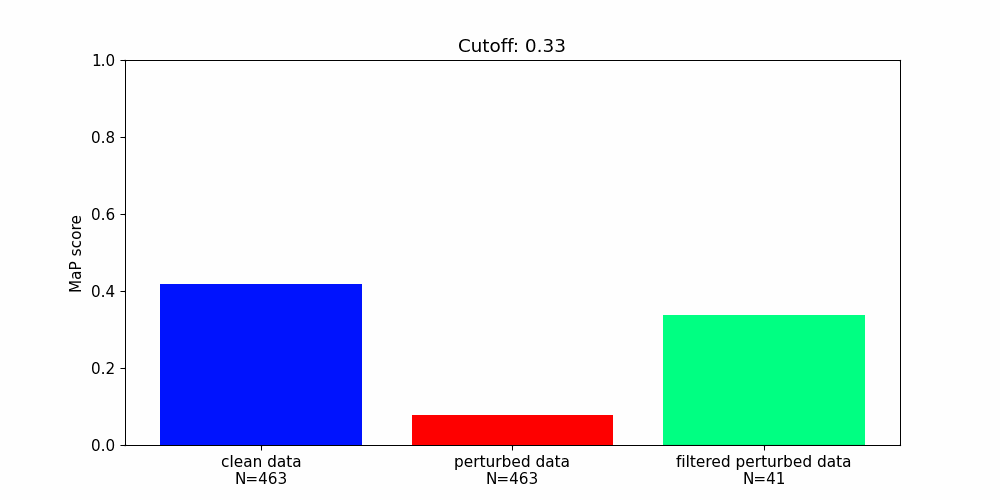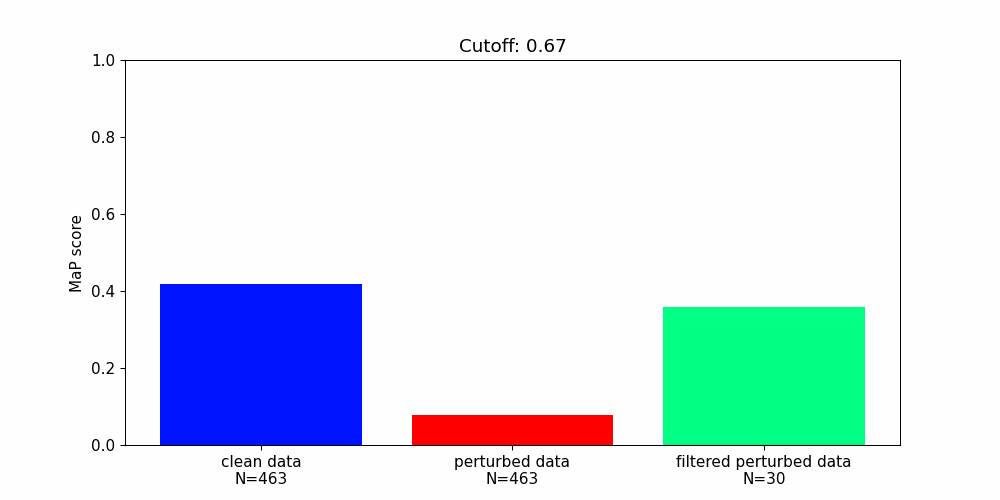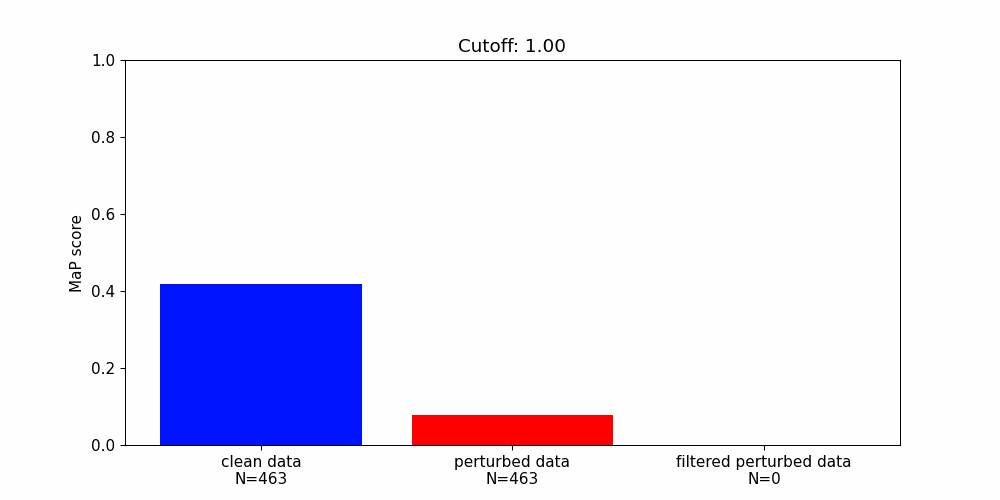
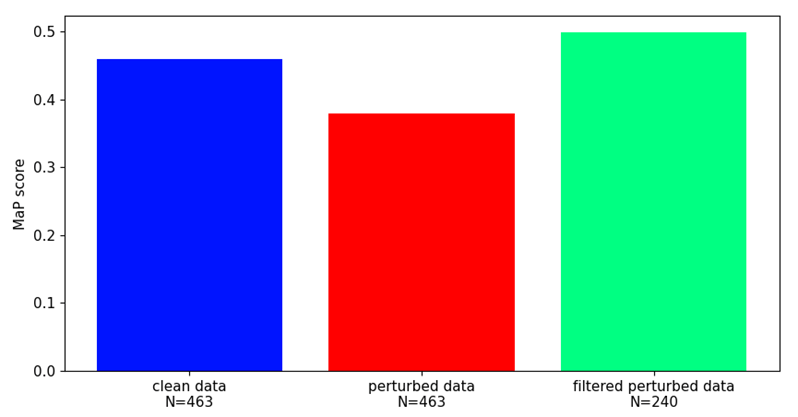
Our findings highlight the importance of developing robust defence mechanisms against adversarial attacks.
As companies and governments seek to deploy AI systems in the coming months and years, the need for constant vigilance and ongoing research becomes paramount.
Whilst there are steps that can be taken to protect machine learning components from adversarial attacks they offer only partial solutions.
The battle between attackers and defenders is an arms race, requiring continuous development of defence methods and a deep understanding of attack techniques to keep ML-based systems secure.
As we move forward, the ability to regularly red-team deployed AI systems will be an essential skill for organisations that seek to harness the power of AI responsibly. We can work towards a future where the benefits of AI can be realised without compromising security and trust by proactively identifying and addressing vulnerabilities.